Only a Single Attribute, Not Multiple Attributes, Can Define Functional Dependence.
Back-up, Subkey, Functional Dependencies, Normalization
Introduction
One of the major goals of relational database design is to prevent unnecessary duplication of data (redundancy). In fact, this is 1 of the main reasons for using a relational database instead of a "flat file" that stores all information in ane table. Sometimes we volition pattern a class that seems to be right, only to find out in the relation scheme or in the table itself that nosotros have a problem.
Example: Contacts
Almost every personal productivity program today includes some sort of contact managing director. A "contact" is a person who could be a business acquaintance or simply a friend or family unit member. Many of these programs have a very simplistic ane-table model for the contact information, which probably has a respective UML class diagram as shown below (omitting phone numbers for the moment)

It may not exist obvious that this model has a trouble, until you wait at the Contacts table with some typical data filled in, every bit illustrated below.
| George | Barnes | 1254 Bellflower | 90840 | Long Beach | CA |
| Susan | Noble | 1515 Palo Verde | 90840 | Long Beach | CA |
| Erwin | Star | 17022 Brookhurst | 92708 | Fountain Valley | CA |
| Alice | Buck | 3884 Atherton | 90836 | Long Embankment | CA |
| Frank | Borders | 10200 Slater | 92708 | Fountian Valley | CA |
| Hanna | Diedrich | 1699 Studebaker | 90840 | Long Embankment | CA |
Detect the repeated information in the urban center and state attributes. This is not only redundant data; it might also be inconsistent information. (Can you spot the "typo" to a higher place?)
Functional dependencies, subkeys, and lossless join decomposition
To understand why we have a problem, we first have to understand the concept of a functional dependency (FD), which is simply a more general concept of the super cardinal constraint. If X and Y are sets of attributes, and so the notation X→Y is read "10 functionally determines Y" or "Y is functionally dependent on 10." This defines a constraint on any table whereby if any two rows take the same value for X, then the ii rows must have the aforementioned value for Y. That is, given a value for X (no matter how many rows may have that same value), it maps to only 1 unique value for Y.
Detecting back-up
A super key ever functionally determines all of the other attributes in a relation (too as itself). If yous are not quite sure why this is the instance, consider a table in which there are 2 rows with the same value for the super cardinal and apply the definition of FD above. Informally, we say a super key FD is a "good" FD. A "bad" FD happens when nosotros accept an attribute or set up of attributes that functionally decide some but not all of the attributes in the relation. Nosotros phone call such set of attributes a subkey of the relation, as it determines simply a subset of the attributes, non all of the attributes, the style a super key does.
Thus, a subkey dependency enables us to detect when a relation scheme has back-up; that is, when a tabular array using the scheme will contain unnecessary duplication of information. A relation scheme has back-up whenever there is a subkey dependency. In such a case, any table following the relation scheme will redundantly store information about the attributes adamant by the subkey.
Preventing/Removing redundancy
There is a very simple 4-step style to set up the problem with a relation scheme that has redundancy, as detected by the presence of a subkey. In the steps given below, the scheme with back-up is R and the subkey is represented by the FD West→Z, where each of Due west and Z is a set of attributes that is a subset of the attributes in R.
- Replace R past two schema, R1 and R2 as described in the following steps.
- Assign R1 the attributes in the wedlock of the attributes in the subkey FD. That is R1={W ∪ Z}. Since W→Z, past definition, W is a superkey of R1.
- Assign Rtwo the gear up of attributes {R - Z}, that is, all the attributes in R except those in Z, the attributes on the right-hand-side of the subkey FD
- Both Rane and Rtwo share W in mutual. In R1, Due west is a superkey and in Rtwo it becomes a foreign key.
The "bad" subkey dependency has been removed considering we've moved the attributes that were functionally dependent on West to another scheme, and we've made W the super cardinal of that scheme.
The instance below illustrates this process.
Instance: detecting and removing back-up in Contacts
In our contacts example nosotros started above, the zipCode is a subkey of the Contacts relation scheme. It is non a super key for the entire table, just it functionally determines the urban center and state, zipCode→{city, land}. (If y'all know the nix lawmaking, you can always find the city and land, although, you might need all 9 digits instead of the five shown in the sample tabular array.) The opposite is not true, because a city has more than one zip code, similar Long Embankment CA in this example.
We can depict the functional dependencies visually in the relation scheme, equally shown in the following figure.
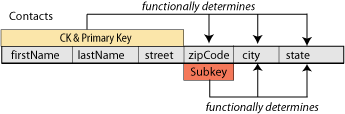
Applying the 4-stride process described above, we will supersede the single relation scheme database with two relation schema. For readability, we proceed the same name for one of our scheme; thus, we become from the relation scheme diagram above to the one shown in the next figure. In this revised model, we will have a many-to-one human relationship between the two schema since one has a FK that references the PK of the other scheme.
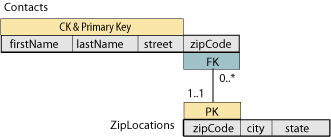
The new Contacts table will look like the onetime one, minus the city and state fields. The new ZipLocations table, shown below, contains but one row per aught code. Joining this table to the Contacts (on matching zipCode pk-fk pairs) will produce the aforementioned information that was in the original tabular array. This property, whereby the information modeled in one database is not lost when the database is redesigned as we've washed here is formally called the lossless join holding of a decomposition of the original table.
| 90840 | Long Beach | CA |
| 90836 | Long Beach | CA |
| 92708 | Fountain Valley | CA |
Subkeys and normalization
Normalization means following a procedure or fix of rules to insure that a database is well designed. Most normalization rules are meant to eliminate storing redundant data (that is, unnecessary indistinguishable data) in the database. The procedure presented in the previous section removes redundancy that is ever a consequence of subkeys. In fact, that procedure is one stage of the BCNF decomposition algorithm which will exist covered in another article.
If there are no subkeys in whatever of the tables in your database, you have a well-designed model according to what is normally called third normal form, or 3NF. Really, 3NF permits subkeys in some very exceptional circumstances that we won't discuss here; the strict no-subkey grade is formally known as Boyce-Codd normal grade, or BCNF.
Some textbooks use the terms partial FDs and transitive FDs. Both of these are subkeys—the beginning where the subkey is function of a primary cardinal, the second where it isn't. Both can be eliminated by the process presented in this article.
Correcting the UML class diagram
When we observe a subkey in a relation scheme or table, we too know that the original UML class was badly designed. The problem, ever, is that nosotros have actually placed two conceptually unlike classes in a unmarried class definition.
In the contacts example, a zipCode is not strictly an attribute of the Contact form. It is an attribute of a ZipLocation class, which we tin depict as "a geographical location whose boundaries have been uniquely defined by the U.S Mail service for postal service commitment."
The zipCode is an external fundamental, created by the USPS for the convenience of its sorting mechanism (not the postal customers). The ZipLocation class has the additional attributes of the city and land where information technology is located; in fact, information technology likewise has the attributes needed to precisely describe its boundaries, although we certainly do not need to represent these in our database. The geographical boundaries would form the "real" descriptive CK if they were included. Equally always, nosotros need to describe the association betwixt ZipLocations and Contacts.
- Each Contact lives in one and only one ZipLocation
- Each ZipLocation may be domicile to many Contacts
As with all one-to-many associations, the association itself identifies which ZipLocation a Contact lives in. If we had started with this course diagram and used our previously defined procedures to map it to the relational model, we would have produced exactly the same relation scheme that nosotros developed with the normalization process above. This speaks to the importance of a well-designed UML class diagram; though, to become a adept designer, 1 must build hundreds of database models and exist exposed to a variety of different contexts or enterprises.

Source: https://web.csulb.edu/colleges/coe/cecs/dbdesign/dbdesign.php?page=subkeys.php
0 Response to "Only a Single Attribute, Not Multiple Attributes, Can Define Functional Dependence."
Post a Comment